In Clean Code, Uncle Bob proposes two rules for good functions: “The first rule of
functions is that they should be small. The second rule of functions
is that they should be smaller than that.” Useful rules, but Clojure
requires one more: they’re still not small enough.
Functional
languages and immutable data make reasoning easy by making functions
simpler. Functions take input, transform it, and return new output. Data passes
through functions, flowing rather than mutating. Complicated functions
make simple
hard, and they
can be dangerously easy to write.
Hyperbole aside, there really are two simple rules for functions: they
should be small, and do one thing. In his presentation on
functions, Uncle Bob describes a simple
algorithm for cleaning up crufty functions:
Pick a function.
Extract functions until it does one thing.
Recur on extracted functions.
Instead of a contrived wombat example, I’ll use one of my own
disgusting old 4Clojure solutions as an example of atrocious code. (But cut me some slack! I was
young and naive.)
Here’s the problem:
“Write a function which takes a collection of integers as an argument.
Return the count of how many elements are smaller than the sum of
their squared component digits. For example: 10 is larger than 1
squared plus 0 squared; whereas 15 is smaller than 1 squared plus 5
squared.”
Like nested blocks in other languages, code that sprawls rightward
indicates a problem—and it can happen fast in Clojure.
To start, we’ll extract lt-sqd-components from the let binding.
(This is a common, awful 4Clojure hack for defining a named function
inside an anonymous one, though the discerning 4Clojurist uses letfn).
The original function is almost readable, but we can do better. It
looks like I didn’t understand filter when I wrote this: the extra
map is redundant since lt-sqd-components is already a predicate function that
returns true or false.
And now the recursive step. Let’s look at the terribly-named
lt-sqd-components. Each line in its let binding does something
different. One splits a number into a sequence of its digits:
One more function to extract: the let binding should be its own
function. One might argue that this function does one thing—all it
does is check whether a number is less than the sum of its squared components!
But it’s operating on several different levels of abstraction: digits,
a sequence of digits, and their sum. A helpful guideline is limiting
functions to one level of abstraction. In this case, the function
should only know about the sum.
On to sum-of-squared-digits. We can transform the let binding into a function using the
threading macro (as suggested in the comments on my last post).
And there it is—clean, readable functions at all levels of
abstraction, minimal nesting, and nothing longer than three lines.
Starting from the top, low-level functions build into bigger
abstractions through combination and composition. Each step is easy to
read and comprehend.
As Uncle Bob puts it in Clean Code:
Master programmers think of systems as stories to be told rather than programs to be written. They use the facilities of their chosen programming language to construct a much richer and more expressive language that can be used to tell that story. Part of that domain-specific language is the hierarchy of functions that describe all the actions that take place within that system. In an artful act of recursion, those actions are written to use the very domain-specific language they define to tell their own small part of the story.
Extract. Simplify. Recur. Take the time to consider each line, and clean code comes naturally.
I spent this evening throwing together a simple site that uses the
HTML5 Geolocation API.
(Link here. Warning: politics!)
The API enables the sort of services that feel magical. In this case,
it took just a little Javascript to retrieve and display contact
information for a user’s Congressional representatives based on
location. (The awesome Congress
API from Sunlight Labs
helped too). In an earlier experiment, I used webcam access with
getUserMedia() and feature
detection to make a scavenger hunt
clue accessible only by holding up a special image in front of the
camera.
But before the giddy magic of HTML5 come terrifying requests from the
browser and a terrible user experience. Chrome “wants to use your
location.” But for what? And how much does it know? Firefox asks if you’d “like to share your camera.” For how long? There’s
no explanation of why or what the site wants to do with the data. The
most likely questions for most users are met with only a chance to
“Deny” or “Accept” an unknown contract. Perhaps this is a problem to
be solved by explanations on the page itself, but the ability to provide a simple message
would be a huge improvement, just by offering an explanation.
I came to 8th Light for a chance to write Clojure, and in the last few
weeks, the lofty dream of slinging s-expressions during my day job
has finally come true. (Apprentices are compensated at a flat rate of
$0.002 per parenthesis). After spending three months learning rules
and practices for writing clean object-oriented code, I’m now
mapping them to functional programming.
Over the next few posts, I’ll try translating some of the guidelines
for clean code to Clojure. Like any style guide, there will be room
for opinion, so don’t hesitate to leave comments or offer suggestions.
Clean Code is worth the cover price for Chapter 2 alone. Its
advice is simple: use meaningful, clear names that reveal intent.
This rule probably seems obvious, but the value is in its side
effects. Taking the time to scrutinize every name requires
the sort of mindfulness and thought that produces clean code. In
addition to Uncle Bob’s general guidelines for good names, here are a
few Clojure-specific rules on naming.
Verbs rule
Clojure’s categorical imperative: act in the Kingdom of
Verbs.
Functions do things, and their names should describe the things they
do. This is usually an easy rule to follow, but functions that build
or return data structures can be tricky. Make-user-map is better
than user-data. Render-footer is better than footer alone.
But nouns are useful
Verbs are great, but they’re even greater when they have objects. A name like
remove-temporary-files is much clearer than clean-up.
Nouns are also useful inside functions. I find my tolerance for
repetition far lower in Clojure than in other languages: if I use an expression more
than once, I’ll almost always put it in a let binding and give it a
name. Inside functions that compose multiple transformations on some
data structure, extracting intermediate steps into values in a let
binding can be very helpful.
Good nouns are also helpful when destructuring
values, which is awesomely useful but sometimes hard to read. Prefer
putting them in let bindings to cramming them in the argument list,
except for very simple cases.
The one first-class exception to verbs everywhere is adjectives for
predicates (functions that return true or false, like odd? and
seq?). These should always end in question marks and always return
either true or false.
12
(defn all-wombats?[coll](every? (wombat?coll)))
Use the best name…
Clojure has a large set of core functions, and sometimes the clearest
name for a function will collide with one of them. Use it anyways!
This is why namespaces are useful. Similarly, don’t worry if the best
name is a long one–it’s easy to rebind it to a new name when required.
…But don’t mislead
That said, make sure it really is the best name. Long names often
indicate functions that can be split: invert-and-multiply and
find-and-replace should probably be split in two. (Hint: and is a
great clue). If a function’s name collides with a core function or
incorporates a common name, it should act the same way: if table-map
doesn’t apply a function to every cell in a table, it has the wrong name.
Dynamic vars wear *earmuffs*. Try not to use them.
Simple format transformations often use an arrow, e.g.: cljs->clj,
html->hiccup, hex->bytes.
Make side effects explicit
Clojure does a great job separating value, state, and
identity.
Clojure programmers should, too. If a function changes state or has
side effects, its name should reflect it. Functions that mutate
state like swap! and reset! end with a bang. Side effects hiding
elsewhere should also be explicit: if format-page saves a file to
disk, it should be format-and-save-page (or even better, two
separate functions).
UPDATE: See also the Clojure Style Guide, a concise, comprehensive community-driven document with many more guidelines on clean Clojure.
Although my Github projects have always included open source
licenses, I haven’t made many
contributions to projects people actually use – at least until this week, when I submitted my first real pull requests. After learning a little Java from my Tic-Tac-Toe and server project, I managed to close an issue I opened six months ago on Spyglass. And I’ve spent most of this weekend hacking in Ruby on Exercism.io, a code koan site that focuses on expressive, readable code.
Not long ago, most software seemed static and untouchable: I treated the libraries and tools I used as artifacts of “real programmers” imbued with a special aura. Slowly, over the last few months, that category has dissolved. Most of the code I touch is no doubt still written by people smarter than me, but suddenly it seems malleable and open for extension.
This, I think, is an underrated benefit of test-driven code. Even when
I still feel like I’m faking it, I have tests that tell the truth: the
code works as intended. But for learning to test, I don’t think I’d
have developed the confidence to jump into an established project and
commit without fear. Writing docs and working from open issues are a
good start, but to really contribute, the first step is writing tests.
The idea at the heart of agile development is really very simple: many
incremental, functional improvements create more value than one big,
centralized push. At 8th Light, we demo completed features to our
clients at the end of each weekly iteration. It’s a chance to show
clients that we’re making progress and creating tangible value.
Perhaps more important, it shortens the feedback loop between feature
ideas and implementation.
A good user story creates “business value.” But note the “business.”
There are many story-like tasks that create lots of value for
developers. Refactoring crufty code into something more stable and
extensible always extends its lifespan. Speeding up the test
suite might mean writing twice as fast. A new design pattern or
library behind the scenes can eliminate scores of future headaches.
And yet none of these improvements are visible, and none really create
business value. They all have second-order effects on business value,
usually on scales longer than one week, but the immediate effects are invisible.
It’s easy to spend a whole week on pseudostories with nothing visible
to show. (I’ve certainly done it!) And it’s easy to feel resentful
when lots of work looks like nothing new at all. But consider a
client’s perspective and invisible efficiencies start to look pretty
lame: imagine a carpenter showing off her rad new nailgun (twice as
fast as a hammer!) instead of the house she’s supposed to be building.
Unseen improvements are hugely helpful, but they don’t count if they
aren’t visible. That doesn’t mean they can’t be made to count.
It can require creativity, but it’s possible to make unseen
improvements more obvious–show, don’t tell, as the writer’s adage
goes. Show how using a repository makes it easy to swap in new data sources.
Show the new views that reuse carefully extracted components. Show a
new feature that Clojurescript made possible. Setting visible goals
along the way makes unseen value clear.
I’ve been a Gmail user for my entire adult life. Ever since I
abandoned my old AOL inbox on the family PC, Gmail has simply been
email. I’ve never used folders, only labels. I’ve never deleted
old messages to save space, but archived everything. I’ve always
expected full-text search, aggressive spam filtering, and continuous
access from any device.
As I’ve archived year after year of new messages, I’ve become less
comfortable storing my entire indexed email history on someone else’s
servers, where they can be scanned and
searched at
will. And yet in practice , I’ve always traded off privacy against
convention and
convenience.
In part, this is because it’s long been a discontinuous decision: even a
small amount of extra control or privacy required giving up all the
modern conveniences of webmail at once. No desktop client came close to the features of Gmail, so I never made the switch. But now that
I spend most of my time in a terminal, I’ve finally found a client
that provides a pretty good compromise: sup.
Sup is not something I’d set up for my Mom, but Rubyists and Unix
geeks will feel right at home. It’s a
curses
based mail client written in Ruby with excellent full text search out
of the box. In addition to offering archiving, labels, and search,
it’s built on top of extensible tools like offlineimap, msmtp, and gpg, and
scriptable in Ruby.
The official docs are very good (and thus don’t need to be repeated),
but these are the sections I found most helpful in order:
For now, sup doesn’t do two-way IMAP syncing, so messages I archive
stay on my machine. In my case this is a feature, not a bug: I now
have a permanent searchable archive stored locally that won’t change
if I delete messages from my Gmail account. I can keep the last few
weeks of mail on the Gmail server, accessible from my phone and the web (and seriously, when
was the last time you looked at an email more than a month old?), and
everything else securely archived on my own drive.
It would be a mistake to consider my sup setup much more private than
plain Gmail. My messages still travel across the internet in cleartext and pile up
in my correspondents’ inboxes. (Sup integrates nicely with GPG for
ad hoc encryption). They’re probably still stored in Google
backups
and no doubt snarfed and sent off to
Bluffdale.
I am probably not paranoid enough, but I believe Google’s claims that they really do erase deleted
messages, and keeping my own archive raises the cost of compromising
or reconstructing my entire history by a little bit, without
sacrificing the features I’ve become so dependent upon.
I’m very fond of Speclj, the simple, flexible Clojure spec runner we
use at 8th Light. Speclj now has a ClojureScript
counterpart, but like many things
ClojureScript, it requires some classpath juggling and configuration
to get everything working nicely. To save my future self the hassle, I
put together a basic project template with Speclj and Specljs tests
and autorunners both preconfigured.
If you’re using Leiningen 2, it’s as easy as:
$ lein new specljs <your project name>
Leiningen will download the template from Clojars automatically.
To start the Speclj autorunner from inside the project directory:
$ lein spec -a
Specljs tests are configured to run whenever the ClojureScript
compiles. To watch for changes, rebuild and run tests automatically,
start the cljsbuild auto-compiler:
$ lein cljsbuild auto
To run specljs tests once:
$ lein cljsbuild test
If you’re using pre-2.0 Leiningen, you can find the template on
Clojars and the source on GitHub.
Over the past two weeks, I’ve been working through The Web Application
Hacker’s
Handbook.
Although it’s not part of the 8th Light core curriculum, it ought to
be: it’s a comprehensive catalog of web security mistakes and a great
introduction to thinking about vulnerabilities from an attacker’s perspective. The only gripe I have
with the authors is their penchant for plugging expensive closed-source software
and online training. Fortunately, I’ve found plenty of free
alternatives. Here are a few of the essential tools I’ve found for
developers interested in web security.
VirtualBox
Every tool in my pentesting kit depends on
VirtualBox. Working in virtual machines
keeps my security tools separate from my development environment, and
allows me to practice attacking hideously vulnerable applications in
quarantine. VirtualBox includes excellent network configuration
options, including completely virtualized local networks that make it
easy to keep things compartmentalized.
Kali Linux
Kali Linux, formerly BackTrack, is a
specialized Debian distribution that includes hundreds of built in
security tools. I can’t begin to imagine the time I might have spent
with Homebrew installing and configuring everything included here. The tools included with Kali are many and powerful, and
I’ve discovered a new fuzzer, proxy, or scanner to try for every topic
in the book.
Zed Attack Proxy
The authors of WAHH frequently plug their own Burp Suite, a closed-source
intercepting proxy that costs $300 per user per year to do anything
useful. Zed Attack
Proxy,
developed by the Open Web Security
Project, is completely free, Apache
licensed, and just as good an educational and testing tool.
(It’s included in Kali, along with the free
edition of Burp). Hacking tools are not always the most carefully
crafted software, but ZAP is an extremely stable, very pleasant
exception. WebScarab, also by OWASP, is another good free alternative.
SQLMap
I remember the joy of my first successful SQL injection like it was
last Thursday. (It was last Thursday, but that’s beside the point).
The thrill of breaking in with a well placed apostrophe and couple of
dashes takes a while to wear off, but diminishing returns are likely to
set in after 50 handcrafted variations on the same GET parameter.
Fortunately, there’s
SQLMap, which almost makes
it too easy, automating the entire process of finding and exploiting SQL injection vulnerabilities.
All these tools are no fun without something to (safely, responsibly, legally)
attack. Browsing through WAHH, I was excited to see lots of links to
online interactive labs illustrating almost every concept. I was less
excited to discover that they’re completely proprietary and cost
$7/hour. Fortunately, there are plenty of open alternatives:
Metasploitable
Metasploitable2
is an intentionally vulnerable virtual machine configured to run
several vulnerable web applications on port 80 by default, including
Damn Vulnerable Web App and
Mutillidae.
Before booting it up, please make sure your network settings are
configured
correctly: it should
never ever be exposed to users on your network or the internet.
RailsGoat
I’m not reading WAHH to become a professional pentester. I’m doing it
to learn how to develop safe web applications, and we write lots of
them in Rails. RailsGoat (yet
another OWASP project) is a vulnerable Rails application with built-in
documentation and examples of the top
10 web
vulnerabilities. Best of all, each one includes code samples, which
are especially useful for a developer like me trying to avoid writing
a goat of my own.
OWASP
Many of these resources come courtesy of OWASP, the Open Web
Application Security
Project. In addition to
developing lots of free tools, they’re an excellent resource for
learning about web security.
It’s time for my first code
kata,
and on Colin’s suggestion, I’m starting with a classic: prime
factorization.
The problem description is simple: write a function that takes an
integer n and returns a list of its prime factors in ascending order.
That leaves lots of room for creativity, and in my few months at 8th
Light, I’ve seen several interesting solutions, including Objective-C
and
Erlang.
I’ve been meaning to learn Clojure’s core.logic library for a while,
so I decided to come up with a logic programming solution.
If you haven’t yet checked out core.logic, there are a growing
number of resources on the web. To get up to speed, I worked through David Nolen’s logic tutorial, the Magical Island of Kanren, the
core.logic
Primer,
and a few chapters of The Reasoned
Schemer.
Hopefully, following along with my test cases will explain the subset
of logic functions in my solution.
On to the tests! The declarative aspect of logic programming feels
well-suited to a mathy problem like this. Instead of describing how to
factorize, I’ll write a few definitions and let the logic engine
handle the rest. The strategy I have in mind is the same simple one I learned in
8th grade algebra: start with a composite integer, and decompose it
into a factor tree whose leaves are prime factors.
To start, I’ll define “factor pairs”: a vector of two integers that
multiply to another. So, [2 3] is a factor pair of 6, [1 23] a
factor pair of 23. Here’s the most general test I came up with:
core_spec.clj
123456789
(ns prime-factors.core-spec(:require[speclj.core:refer:all][prime-factors.core:refer:all]))(defmacro they[&args]`(it~@args))(describe"Factor pairs of n"(they"contain two elements"(should='([_0_1])(factor-pairs81))))
There’s a lot of syntax right off the bat, but this test isn’t as
confusing as it might look. So far, I’ve found it easiest to understand logic programming as
describing a set of constraints on a solution. This test describes the
first constraint: factor pairs are vectors of two elements.
Here, _0 and _1 represent reified, unbound logic variables: symbolic
representations of logic variables that can take on any value. (The
numbers at the end indicate that they’re two different variables: _0
and _1 can take on different values). So this
test simply describes the most general constraint: the factor-pairs
function should take something as an argument and return a list of
vectors of two things–any two things!.
The run* function is the, uh, core of core.logic, used to set up
problems for the logic engine to solve. It returns a list of all the
solutions that match the constraints defined inside. The fresh form
inside of run* is
analogous to let: a way to declare local logic variables. The first
two lines say “Find all
the solutions where pair, factor1, and factor2 meet these
constraints,” and the third describes the only constraint: “A pair is a
vector of two elements, factor1 and factor2”.
Note that I’m ignoring the number argument! At this point
(factor-pairs 81), (factor-pairs 72), and (factor-pairs 23) all
return the same result. For now, calling this function factor-pairs
is a little misleading, since it returns the equivalent of all
possible pairs of two things. But now that the tests pass, we can add
another constraint:
core_spec.clj
1234567891011121314151617181920
(ns prime-factors.core-spec(:require[speclj.core:refer:all][prime-factors.core:refer:all]))(defmacro they[&args]`(it~@args))(defn should-all[predicatecollection](should(every? predicatecollection)))(defn in-interval?[lowhigh](fn [pair](every? #(and (>= %low)(<= %high))pair)))(defn two-elements?[pair](= 2(count pair)))(describe"Factor pairs of n"(they"contain two elements"(should-alltwo-elements?(factor-pairs81)))(they"are defined between 2 and n"(should-all(in-interval?281)(factor-pairs81))))
Here, I’ll describe the next constraint: factor pairs should only be
defined between 2 and n. (Yes, a pair like [1 23] is technically a
pair of factors, but it’s not very useful for my prime factorization purposes).
I may be open to a little TDD legal trouble
with this test update, but I’ve added a couple helper functions to
keep the tests as declarative as possible. Should-all asserts that a
predicate matches for every element in a collection. In-interval?
tests whether a pair is in the range low to high, inclusive.
Hopefully, Two-elements? explains itself. Since factor-pairs will
now return a list with many elements, I’ve generalized the original test.
It only takes one line to add the extra constraint:
The new line declares that factor1 and factor2 must both be in the
finite interval 2-number. Factor-pairs is still something of a
misnomer: it now returns the Cartesian product of all numbers
2-number. But it’s a step closer. I’ll add one more constraint:
core_spec.clj
12345678910111213141516171819202122232425
(ns prime-factors.core-spec(:require[speclj.core:refer:all][prime-factors.core:refer:all]))(defmacro they[&args]`(it~@args))(defn should-all[predicatecollection](should(every? predicatecollection)))(defn in-interval?[lowhigh](fn [pair](every? #(and (>= %low)(<= %high))pair)))(defn two-elements?[pair](= 2(count pair)))(defn multiply-to?[n](fn [[factor1factor2]](= n(* factor1factor2))))(describe"Factor pairs of n"(they"contain two elements"(should-alltwo-elements?(factor-pairs81)))(they"are defined between 2 and n"(should-all(in-interval?281)(factor-pairs81)))(they"equal n when multiplied"(should-all(multiply-to?81)(factor-pairs81))))
Factor pairs contain two elements between 2 and n that equal n when
multiplied. That’s a complete definition of a factor pair, and adding
the third constraint completes the function:
Here, eq converts an arithmetic expression into a constraint, as
long as the logic variables are defined over a finite domain. So the
final constraint simply says number must equal factor1 times
factor2. If you’re not convinced by the tests, try it in a REPL:
There are some properties here that I’ll use to my advantage. First,
by default, factor pairs are ordered by the first factor, ascending.
Second, I’ve already created an implicit definition of primes: numbers
that return an empty list of factor pairs. I’ll add it as a test for
clarity:
core_spec.clj
1234567891011121314151617181920212223242526272829
(ns prime-factors.core-spec(:require[speclj.core:refer:all][prime-factors.core:refer:all]))(defmacro they[&args]`(it~@args))(defn should-all[predicatecollection](should(every? predicatecollection)))(defn in-interval?[lowhigh](fn [pair](every? #(and (>= %low)(<= %high))pair)))(defn two-elements?[pair](= 2(count pair)))(defn multiply-to?[n](fn [[factor1factor2]](= n(* factor1factor2))))(describe"Factor pairs of n"(they"contain two elements"(should-alltwo-elements?(factor-pairs81)))(they"are defined between 2 and n"(should-all(in-interval?281)(factor-pairs81)))(they"equal n when multiplied"(should-all(multiply-to?81)(factor-pairs81))))(describe"Prime numbers"(they"have no factor pairs"(should='()(factor-pairs23))))
Now I’ll move on to decomposition. If you’ve watched a prime factors
kata before, you’ve probably seen a few standard tests: start by
testing 1, then 2, then 3, and then composites. Here’s where something
similar comes in:
(ns prime-factors.core-spec(:require[speclj.core:refer:all][prime-factors.core:refer:all]))(defmacro they[&args]`(it~@args))(defn should-all[predicatecollection](should(every? predicatecollection)))(defn in-interval?[lowhigh](fn [pair](every? #(and (>= %low)(<= %high))pair)))(defn two-elements?[pair](= 2(count pair)))(defn multiply-to?[n](fn [[factor1factor2]](= n(* factor1factor2))))(describe"Factor pairs of n"(they"contain two elements"(should-alltwo-elements?(factor-pairs81)))(they"are defined between 2 and n"(should-all(in-interval?281)(factor-pairs81)))(they"equal n when multiplied"(should-all(multiply-to?81)(factor-pairs81))))(describe"Prime numbers"(they"have no factor pairs"(should='()(factor-pairs23))))(describe"Decomposition"(it"decomposes 1 into itself"(should='(1)(decompose1))))
(ns prime-factors.core-spec(:require[speclj.core:refer:all][prime-factors.core:refer:all]))(defmacro they[&args]`(it~@args))(defn should-all[predicatecollection](should(every? predicatecollection)))(defn in-interval?[lowhigh](fn [pair](every? #(and (>= %low)(<= %high))pair)))(defn two-elements?[pair](= 2(count pair)))(defn multiply-to?[n](fn [[factor1factor2]](= n(* factor1factor2))))(describe"Factor pairs of n"(they"contain two elements"(should-alltwo-elements?(factor-pairs81)))(they"are defined between 2 and n"(should-all(in-interval?281)(factor-pairs81)))(they"equal n when multiplied"(should-all(multiply-to?81)(factor-pairs81))))(describe"Prime numbers"(they"have no factor pairs"(should='()(factor-pairs23))))(describe"Decomposition"(it"decomposes 1 into itself"(should='(1)(decompose1)))(it"decomposes primes into themselves"(should='(2)(decompose2))(should='(3)(decompose3))(should='(17)(decompose17))(should='(23)(decompose23)))
I’ll get back to passing with a small tweak. Instead of returning
'(1), decompose should check if a number has any
factor pairs. If not, return the number.
(ns prime-factors.core-spec(:require[speclj.core:refer:all][prime-factors.core:refer:all]))(defmacro they[&args]`(it~@args))(defn should-all[predicatecollection](should(every? predicatecollection)))(defn in-interval?[lowhigh](fn [pair](every? #(and (>= %low)(<= %high))pair)))(defn two-elements?[pair](= 2(count pair)))(defn multiply-to?[n](fn [[factor1factor2]](= n(* factor1factor2))))(describe"Factor pairs of n"(they"contain two elements"(should-alltwo-elements?(factor-pairs81)))(they"are defined between 2 and n"(should-all(in-interval?281)(factor-pairs81)))(they"equal n when multiplied"(should-all(multiply-to?81)(factor-pairs81))))(describe"Prime numbers"(they"have no factor pairs"(should='()(factor-pairs23))))(describe"Decomposition"(it"decomposes 1 into itself"(should='(1)(decompose1)))(it"decomposes primes into themselves"(should='(2)(decompose2))(should='(3)(decompose3))(should='(17)(decompose17))(should='(23)(decompose23)))(it"decomposes 2 * a prime into 2 and itself"(should='(22)(decompose4))))
Decompose already includes the base case at the bottom of of the
prime factor tree. If I feed it a number that’s not prime, it should
decompose its factors until it runs into a prime. Concatenating the
results should return a nice list of prime factors:
(ns prime-factors.core-spec(:require[speclj.core:refer:all][prime-factors.core:refer:all]))(defmacro they[&args]`(it~@args))(defn should-all[predicatecollection](should(every? predicatecollection)))(defn in-interval?[lowhigh](fn [pair](every? #(and (>= %low)(<= %high))pair)))(defn two-elements?[pair](= 2(count pair)))(defn multiply-to?[n](fn [[factor1factor2]](= n(* factor1factor2))))(describe"Factor pairs of n"(they"contain two elements"(should-alltwo-elements?(factor-pairs81)))(they"are defined between 2 and n"(should-all(in-interval?281)(factor-pairs81)))(they"equal n when multiplied"(should-all(multiply-to?81)(factor-pairs81))))(describe"Prime numbers"(they"have no factor pairs"(should='()(factor-pairs23))))(describe"Decomposition"(it"decomposes 1 into itself"(should='(1)(decompose1)))(it"decomposes primes into themselves"(should='(2)(decompose2))(should='(3)(decompose3))(should='(17)(decompose17))(should='(23)(decompose23)))(it"decomposes 2 * a prime into 2 and itself"(should='(22)(decompose4)))(it"decomposes a composite into its prime factorization"(should='(222)(decompose8))(should='(235)(decompose30))(should='(21111)(decompose242))(should='(251123)(decompose(* 235211)))))
This isn’t the fastest way to find prime factors, but it’s no worse
than the typical trial division solution to the prime factors kata.
Using core.logic to declare definitions and constraints on the
solution feels uniquely concise, expressive, and clear, and the
exercise helped me get a more concrete handle on logic programming.
You can find the code from this post (and a few earlier iterations) as
a Gist here.
My latest project involves adding a Flash fallback to replace an
HTML5-based feature in a Rails application. It’s the first time I’ve
tested in Internet Explorer over a virtual machine, and I spent a good
deal of time configuring everything. Here’s a summary of the process
for future VM novices.
Get VirtualBox
First, grab VirtualBox. It may be handy
for more than testing: in addition to
running Internet Explorer, you might want to try a new Linux
distro or do some pen
testing.
Install an IE virtual machine
Microsoft recently rolled out free virtual machine images for IE
testing that greatly simplify the setup process. Download and extract the versions you’re interested in.
Some of these are distributed as full images, but most come as several .rar files and a
self-extracting archive. To extract from the command line:
This should create a new .ova file in the same directory. Open VirtualBox and import it (File > Import Appliance on OS X).
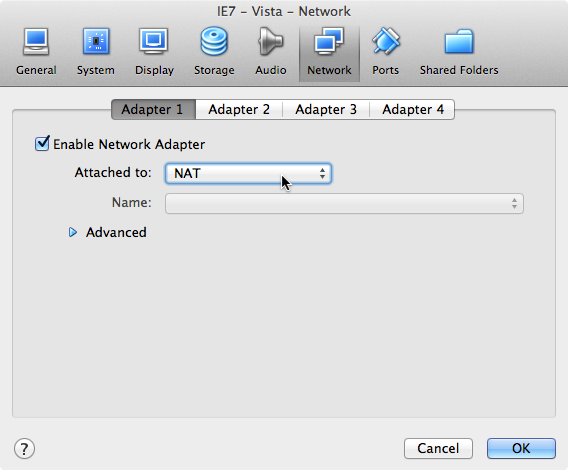
Configure network settings
Select the machine you’d like to connect from and choose Settings >
Network. Make sure the network adapter is enabled and attached to NAT.
(This should be the default setting).
You can access the host machine
from inside the VM at 10.0.2.2–e.g., if you access your Rails dev server at
localhost:3000, you can connect at 10.0.2.2:3000. Unfortunately,
running my Rails dev server from the host machine resulted in
occasional redirects to localhost. Fix this by editing the Windows
hosts file.
The Windows hosts file is available in
C:\windows\system32\drivers\etc\. In XP, you’ll be able to edit it
directly with Notepad. On a Vista VM, you’ll need admin priviliges.
Find Notepad in the start menu, right click, and choose “Run as
Administrator.” Then, edit the hosts file to direct localhost to
10.0.2.2, the default VirtualBox address for the host machine.
1
10.0.2.2 localhost
Run your Rails dev server on the host machine, and connect to
localhost:3000 as usual. Congratulations! You’re ready for the joy of
Internet Explorer. For bonus points, configure Capybara to run in IE.